|
Smart Heating and Estimation of Heating SavingsA Research Project of the Distributed Systems GroupProject period: June 2016 - January 2017 Project descriptionHeating is the main contributor to energy consumption in households. In Switzerland, about 70% of the energy consumption in Swiss households is due to heating. Still, many heating systems run on fixed schedules, ignoring that heating is in principle only necessary when the home is occupied. Modern sensor-based smart thermostats try to optimize upon that.But when do the expected savings justify the installation of occupancy-aware systems?
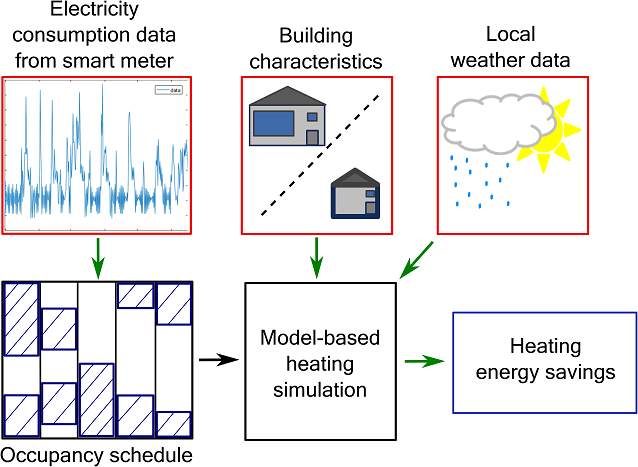
In this project we create a system which estimates the potential savings of a household if an occupancy-based heating
strategy was applied, i.e. the heating would be turned down during absence. The system only relies on few parameters: For (a) meteorological statistics are available for virtually every geographic location and (b) can be estimated accurately enough with a few simple properties of the house (age, size, etc.). However, (c) is quite challenging: Not so much the mean occupancy itself is relevant as the distribution of shorter and longer periods of absence. Intriguingly, occupancy patterns can be inferred automatically using data analytics applied to electricity consumption data acquired by smart meters – even if the electricity consumption of the household is only measured once every 30 minutes, an accuracy of around 85% can be achieved. We use a heating simulation model which takes all these parameters into account and controls the heating in the simulated environment according to a specific strategy, either on fixed schedules or according to the occupancy derived form the electricity consumption. By comparing the amount of energy required the system can estimate the savings potential if applying an occupancy-based heating strategy.
See also the following related items:
Participating ResearchersVincent Becker, Wilhelm Kleiminger |
|
|