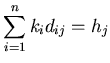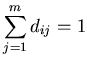Marc Langheinrich1, Atsuyoshi Nakamura,
Naoki Abe, Tomonari Kamba, Yoshiyuki Koseki
NEC Corporation,
C&C Media Research Laboratories
1-1-4 Miyazaki, Miyamae-ku
Kawasaki, Kanagawa 216-8555 Japan
+81-44-856-2258
{marc,atsu,abe,kamba,koseki}@ccm.cl.nec.co.jp
In this paper, we propose a novel technique of adapting online advertisement to a user's short term interests in a non-intrusive way. As a proof-of-concept we implemented a dynamic advertisement selection system able to deliver customized advertisements to users of an online search service or Web directory. No user-specific data elements are collected or stored at any time. Initial experiments indicate that the system is able to improve the average click-through rate substantially compared to random selection methods.
In order for Web advertisement to be effective, advertisers increasingly rely on targeting techniques that invade a user's privacy. Some of the largest commercial sites on the World Wide Web recently agreed to feed information about their customers' reading, shopping and entertainment habits into a central system, mostly without the user's knowledge [10].
Surveys [22] indicate that users are beginning to value their online privacy more and more. Widespread consumer protest last year prompted online giant AOL to reverse it's plans of selling information from its customer database to an online marketing firm [28].
Instead of amassing more and more information about each user, we propose a less intrusive approach: a low-data oriented customization sufficient to capture the short-term interests of users of Web directory and search services. As a first step, we have implemented an advertisement server system for short-term advertisement customization in order to measure the level of adaptivity that is possible with minimal data.
Our system relies only on search keywords supplied by a user to a search engine. Based on the user's current interests (as expressed by the chosen search keyword) the system dynamically selects a best matching advertisement. By only relying on one or more keywords, no user-specific data is collected or retained, allowing us to provide customized advertisements without invading user privacy. Alternatively, in a browsable directory setting, our system observes the URL of the page the user is requesting and selects the most appropriate advertisement for this page.
The following sections will first describe current techniques for advertisement selection, then contrast this with our plans for an unintrusive advertisement system called ADWIZ. After giving some implementation details of our first prototype we will summarize some simple, preliminary experiments we conducted and close with comments on future and related work.
|
|
Figure 1: A typical Advertisement Banner
on the Web. Most banner advertisements on the Web today are GIF or
JPEG files in a rectangular format, suitable for display at the
top or bottom of a Web page. However, many advertisement systems also
support both smaller sizes (for example for displaying them on a
navigation sidebar) and other media formats (such as HTML tables or
even Java programs). |
The technical details of both HTML [19] (the markup language used to describe Web page content) and HTTP [8] (the protocol used to request and transmit Web pages) make it possible to separate page content and advertisement, thus enabling dynamic advertisement selection every time a Web page is requested.
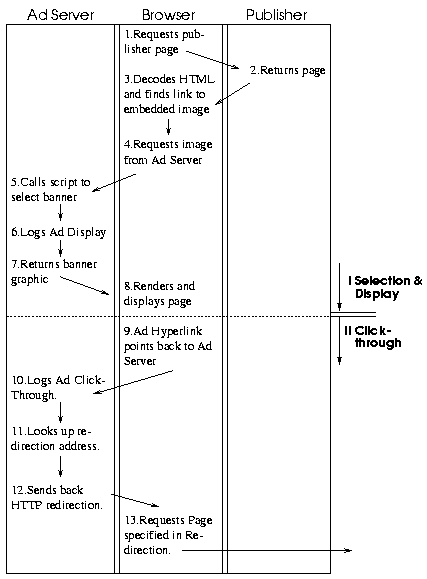
The basic process is outlined in figure 2: the Web page of an online service (the "publisher") contains a link to a banner advertisement. Although the content of the original Web page (step 2) stays the same, the Ad Server will potentially select different banner images for subsequent advertisement requests (steps 5-7).
Once a user shows interest in the displayed banner and clicks on it, the surrounding hyperlink will point back to the Ad Server where a script notes the click and sends a redirection message with the correct advertiser's site back to the originating browser. With a slight delay, the browser will request the correct product information page from the advertiser's server.
|
Figure 2: Online Advertisement - Control & Data
Flow. Embedded HTML images (step 3) and HTTP redirection (step 12)
make it possible to separate page content and advertisement. After
obtaining the page content from the publisher's Web server, the user's
browser will request a dynamically selected advertisement from the Ad
Server (part I). Once the user clicks on the advertisement (part II),
the Ad Server will redirect the user to the appropriate site. |
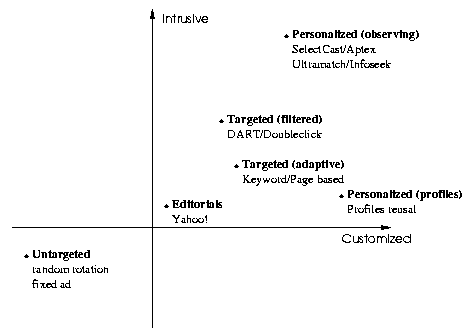 |
Figure 3: Comparison
of Online Advertisement Systems. Traditional advertisement systems
have to balance the tradeoff between improved customization and
increased user surveillance. Separating short-term and long-term
interests allows us to achieve higher customization with less
intrusion of user privacy. |
Using editorial placement mechanisms, such as site specific advertising (for example on a site promoting the use of a certain operating system) or advertisement on topic-based pages (such as a Web directory), user interests directly overlap with the topic of the ad. While no user data needs to be collected, this form of advertisement placement still needs a high grade of monitoring in order to decide the best match between a certain advertisement and the page's content.
Targeted advertisement allows advertisers a greater level of control over who sees their advertisements and raises only minor privacy concerns, since usually no personal identifiable data is collected. However, systems like DoubleClick's DART [7] use unique identifiers to group the collected data by user. In either case, advertisers have to constantly monitor and manually revise their targeting parameters in order to maximize the effectiveness of advertisement placement.
Finally, systems for personalized ad selection put the computer in charge of the constant adaptation of targeting constraints, but require a unprecedented level of user monitoring. Recent reports [10,3] already outline plans to connect such "click-trail" databases with those of traditional mass-mailing companies, containing detailed demographics (income, age, gender) and buying-habit data about each user. Unsurprisingly, over 62% of Internet users do not trust sites collecting their online data [22, 9th survey] and more than two thirds ask for new laws on privacy [22, 8th survey].
Both keywords and page URLs reflect user interest in a certain topic and can be used to customize the displayed advertisement. This information is said to be "short-term" based, since users might have various reasons for looking up a certain article or Web page, that might or might not coincide with their regular interests.
Our "short-term interests" approach, called "Adaptive Targeting" is situated between the targeting-by-filtering and personalization approaches described above (see figure 3). Instead of amassing large amounts of information about the user as it is necessary for traditional approaches, our system can provide highly relevant advertisement with only a single piece of information (keywords or page URLs) by being able to automatically adapt to changes in correlation between this data and the actual advertisements.
Instead of creating more and more sophisticated monitoring applications for Web advertising, we propose to use the readily available information stored in the user profiles of such services. In order to personalize advertisement to fit long-term user interests, such a system could completely rely on the personalization application to collect the necessary user profile information.
The current implementation of our adaptive targeting solution ADWIZ does not yet support long-term interest targeting, but several of our planned extensions to this extent are listed in section 4.2 Future Work. The following section will describe our implementation of a short-term interest based advertisement system, ADWIZ, in more detail.
We will first give a very high level overview of the system's architectural components and its interfaces, and then proceed to describe its core components in more detail. Using empirical results obtain in our initial experiments we will then assess the system's effectiveness.
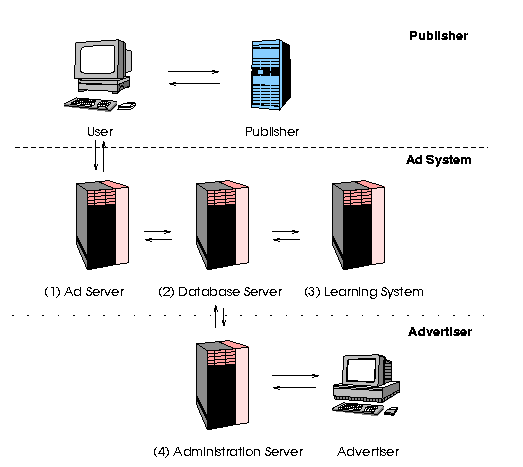 |
Figure 4: System
Overview. The ADWIZ system consists of four parts: The Ad
Server (1) handles requests for advertisements and selects a suitable
banner ad for a search term of Web page; a Database Server (2) acts as
a central storage facility and communication channel; the Learning
System (3) continuously updates the display probabilities for each
advertisement that are stored in the database; while an Administration
Server (4) allows advertisers (and publishers) to maintain and inspect
the system status. |
Through its back end interface, advertisers (and/or publishers) can modify advertisements and their properties, schedule ad campaigns and obtain detailed performance reports. Advertisers can specify constraints similar to those offered in traditional advertisement systems, restricting display of an advertisement to certain target groups. Additionally, a keyword or particular Web page (or a percentage thereof) can be rented for an advertisement, resulting in a minimum guaranteed display rate for queries featuring this keyword or requests for that page.
Since banner graphic display as well as user click-through handling are simple database lookups, we will focus our description here on the the Ad Server's principal module, the Selection Engine. The Selection Engine is responsible for selecting an advertisement from the pool of available banners for a given request (i.e. a search query or Web page request).
Figure 5 shows the data flow within the Selection Engine that corresponds to step 5 in figure 2, the script call for selecting a banner. For simplicity we will assume a request for embedding an advertisement on the result page of a search service (i.e. a keyword based selection), although the same description would apply to the selection of a page based advertisement.
An Input Decoding module first decodes the parameters supplied through the CGI and extracts the set of keywords f1, f2, ..., fn that were used in the query to the search service. The Relevancy Computation module then uses a set of weights - display probabilities for each advertisement given a certain keyword - to compute a display probability P(fi) for each advertisement in the system, given the search terms f1, ..., fn.
The weights are periodically updated by the Learning System using performance data collected by the system and a set of display constraints specified by the advertiser through the system's Advertisement Management System. Using this distribution, the Advertisement Selection module then chooses a particular advertisement adi and returns the graphical banner information back to the user's browser.
Note that the picture in figure 5 is simplified, since transactions between the Management System (i.e. the Administration Server), the Learning System and the Ad Server are all made through the Database Server.
In the click-through case (not shown) the Ad Server simply has to make a note in its performance table (stored in the database) that a selected ad has been "successful" and then redirect the user's browser to the corresponding Web site specified for this ad. This redirection is again transparent to the user, who might in the worst case notice only a slight delay.
 |
Figure 5: The Ad Server's advertisement selection
process. After extracting the search keywords, the Ad Server
retrieves the corresponding weights and computes a display probability
P(fi) for each advertisement in the
system, given the search terms f1, ...,
fn |
The advertiser sets a number of advertisement and campaign Properties (i.e. when should which ad be displayed). The Learning System continuously reads out the currently active advertisements from the Ad Properties and obtains Performance Data regarding each advertisement's click-through performance together with the corresponding keyword and Web page distribution (i.e. the number of times each keyword has been entered as a search term, and the number of times a particular Web page has been requested).
After computing the new display probabilities the Learning System then updates the Selection Data tables, which are consulted by the Ad Server whenever a new advertisement needs to be selected. Given the id of the ad that should be displayed, the Ad Server can then get the banner image and necessary link information from the Ad Properties tables.
After each advertisement display or click-through redirection, the Ad Server will record the displayed or clicked advertisement and keyword pairs (or advertisement and page pairs) in the Performance Data tables, which the Advertiser can use to monitor the system's performance.
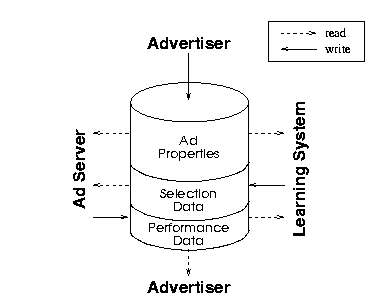 | Figure 6:
Communication via the Database Server. After the Advertiser sets
all relevant Ad Properties, the Learning System obtains
campaign information and Performance Data and computes new
Selection Data (i.e. weights). This information is used by
the Ad Server during advertisement selection. Log information from the
Ad Server is written back into the Performance Data tables,
where it can be accessed by both the Learning System and the
Advertiser. |
The learning engine system allows for both page-driven ads and (search) keyword-driven ads. In the following description of our learning engine, we again assume the latter setting for simplicity.
The basic idea is that the learning engine gathers statistics on the click-through rates for each advertisement-keyword pair, and then adjusts its ad display schedule in such a way that maximizes the total number of clicks.
One complication arises with this approach, however, due to the fact that, in actual advertisement contracts, a minimum number of displays is usually promised for each advertisement. Thus, simply displaying the "best ads" for each keyword will not work, since poorly performing ads may never get displayed for any keywords. The click maximization problem we are dealing with is therefore an optimization problem with constraints. In particular, we can formulate the click maximization problem as a special form of linear programming problem as stated below.
Suppose that we are to probabilistically display m
advertisements
A1,...,Am depending on
which of the search keywords
W1,...,Wn is input. We
first need to calculate the desired display rate
hj for each ad
Aj in the next period (until the learning
engine is invoked next).
This number can easily be computed by taking the promised number of
displays for each advertisement and subtracting from it the number of
times the ad has already been displayed. This figure is then divided
by the number of remaining days in the advertisement's display period
and normalized across all advertisements so that ![]() .
.
We then estimate the input probability ki
of each keyword
Wi and the click-through rate (clicks
per displays) cij of each ad
Aj on each keyword
Wi based on the past statistics.
To calculate the expected keyword input probabilities we simply count
the number of times each keyword has appeared in a query in the past
(using a logarithmic decay factor) and normalize
again so that ![]() . During system operation
each display and click-through of an advertisement is logged together
with the corresponding search keywords that were used to select
it. Thus dividing the number of clicks by the number of displays for
each advertisement-keyword
combination (i.e. Aj and
Wi) gives us
cij.
. During system operation
each display and click-through of an advertisement is logged together
with the corresponding search keywords that were used to select
it. Thus dividing the number of clicks by the number of displays for
each advertisement-keyword
combination (i.e. Aj and
Wi) gives us
cij.
With these estimated quantities we set out to compute a display
probability ("weight") dij that for a given
keyword Wj tells our Selection Engine the
probability with which a particular advertisement
Ai from the list of available ads should be
selected. The corresponding optimization problem
we wish to solve can thus be formulated as the problem of
setting the ad display rates dij for
advertisement Ai on keyword
Wj,
so as to maximize the expected total click-through rate
![]() under the following constraints:
under the following constraints:
Incidentally, many contracts come with so called "keyword rental"
and "inhibitory keywords." These can be naturally incorporated
in the above formulation.
For example, if ad Aj is 30 % rented for keyword Wi,
then we just need to replace the constraint (3)
for dij by the following:
Notice how with this approach the total click rate is maximized when
dij = 0,
but that the system is still able to choose a non-zero value should
display constraints make it necessary. In contrast, it is easy to
check the feasibility of rental (i.e. non-zero) keyword
constraints, since the problem is solvable if and only if
![]() for all i and
for all i and
![]() for all j.
for all j.
The above formulation of linear programming in fact belongs to the so called "Hitchcock-type transportation problem." (One can see this by substituting xij for kidij.) An efficient variant of the Simplex method is known for this class of problems, which uses (for m advertisements and n keywords) only O(mn) space instead of O(mn(m+n-1)) space required by the general Simplex method. (See, for example, [14].) We adopted this method in our learning engine.
There is a subtle issue that need be addressed when we use the linear programming approach. This is the fact that an optimal solution of the above linear programming problem will tend to set most display probabilities dij to 0, and ad-keyword pairs that perform poorly at the beginning may never be displayed again. This way the confidence of estimation of the click-through rate for that ad-keyword pair will never improve. As one can imagine, it can happen that some ads that can potentially perform well on a keyword get unlucky and do badly at the beginning.
We address this issue by setting a minimum display rate for each ad-keyword pair, which is gradually lowered as a function of the sample size. More specifically, we replace the non-negativity constraint (3) with the following:
We evaluated our learning engine using artificially generated data. We constructed probabilistic models of users, namely a probability distribution D(i) for the keyword generation and a conditional probability model C(i,j) for click-through rates conditioned by a keyword and an ad, and used a random number generator to simulate them. We ran our learning engine in the artificial environment thus constructed and measured its performance.
More specifically, the following trial was repeated one million times, while updating the display probabilities dij every 3,125 trials by feeding the statistics obtained up to that point to the learning engine.
|
 | |
 |
|
In the experiment that we report here,
we used models that consisted of 32 ads and 128 keywords.
The 128 keywords were divided into 32 groups of four keywords,
with each group appearing with equal probability. Within each
group, four keywords appear with different probabilities
(with ratios 1:2:3:4).
First, a click-through rate assignment to the 32 ads was created
by hand, including high, moderately high and low click rates.
Then for each of the 32 keyword groups, we created a different
pattern of assignment by rotating the original assignment pattern
and adding some noise. Within each keyword group, the basic assignment
pattern was further modified by multiplying the probabilities by
a random real number in
![]() for each ad Aj.
We had no constraints involving rental or inhibitory keywords.
for each ad Aj.
We had no constraints involving rental or inhibitory keywords.
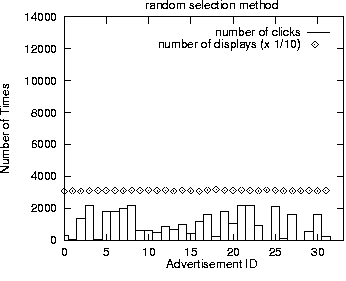
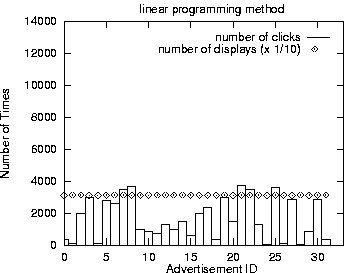
In our evaluation, we compared our learning method with two simple methods: the method of selecting an ad randomly (the random selection method) and the method of selecting an ad with the maximum click-through rate for the given keyword in the current data (the max click rate method).
Figure 7 shows the results of these experiments. The results were obtained by averaging over five runs in each case. The diamond shaped dots indicate one tenth of the number of displays, and the bars indicate the number of clicks. The first figure is the result using the random selection method, the second figure is for the max click rate method, and the last figure is for our method.
 |
|
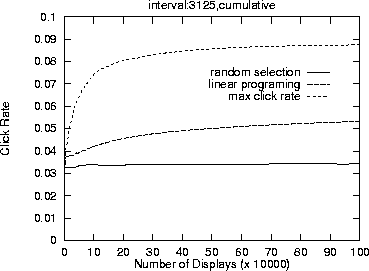
While it is true that the max click rate method achieves the highest total click-through rates, close examination will reveal that with this method half the ads did not get displayed much. Thus, this method is most likely not usable in practice. The number of displays for the ads is balanced for both the random selection method and our method, but the total number of clicks yielded by our method is significantly higher. Figure 8 plots the cumulative total click-through rates achieved by each the three methods over time.
 |
|
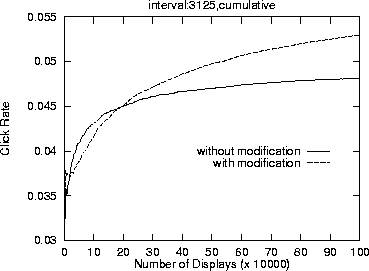
We also ran experiments to evaluate the effect of the modification we described earlier of assuring a minimum number of displays for each ad-keyword pair (4). Figure 9 plots the click-through rates achieved by the version with the modification and the version without it. The click-through rate using the modified version rises more slowly at the beginning since it is doing more exploration, but in the end, it surpasses the vanilla version by a significant margin.
By using an automated, constraint based learning method we are able to
Although a simple selection method that always uses the best performing advertisement achieves the highest total click-through rate in our experiments, the minimum display constraints found in many advertisement contracts today render such strategies useless in practice. Our first prototype has encouraged us to continue our work on unintrusive advertisement customization methods.
[15] describes a system which separates advertisements and publishers' Web sites by introducing an Advertisement Agent. The agent sits between advertisers and the user's browser and merges banner advertisement directly into the currently viewed page, independent of the page itself. A number of companies have introduced similar systems, for example displaying advertisement while the user waits for Web content to download, but these have so far failed to gain widespread acceptance.
A system developed by [4] uses explicit interest solicitation, both through a special form-based interface and by using negative feedback controls next to each displayed banner advertisement. Although this approach is both privacy friendly and promises a high potential for personalization, a real-world deployment has yet to show how much effort the user is willing to make in order to receive customized advertisements.
Other studies [5] suggest that the value of banner advertising goes beyond direct click-through responses, influencing the user even when he or she does not click on the surrounding hyperlink. However, so far no advertiser has adopted any other method for measuring the effectiveness of an ad, rendering click-through maximization performed by our system still the only available benchmark. Finally, [20] reports that other forms of advertisement, such as site sponsorship, might be better suited to get user attention than simple banner ads. Although the level of such promotional advertisement continues to increase, the Internet Advertisement Bureau still sees banner advertisement as the dominant form of online advertising [27].
 Marc Langheinrich received a masters degree in computer science from
the University of Bielefeld, Germany, in 1997. Starting in the fall
of 1995, he spent a year as a Fulbright Scholar at the University of
Washington, where he also completed his thesis work in the field
of information retrieval and software agents. In the fall of 1997
he joined NEC Research in Japan and has since been working
in the fields of personalization and electronic
commerce.
Marc Langheinrich received a masters degree in computer science from
the University of Bielefeld, Germany, in 1997. Starting in the fall
of 1995, he spent a year as a Fulbright Scholar at the University of
Washington, where he also completed his thesis work in the field
of information retrieval and software agents. In the fall of 1997
he joined NEC Research in Japan and has since been working
in the fields of personalization and electronic
commerce.
|
 Atsuyoshi Nakamura received his B.S. and M.S. degrees
in computer science from the Tokyo Institute of Technology in 1986
and 1988. He is presently an assistant manager in the
C&C Media Research Laboratories of NEC Corporation.
His interests have been in the area of machine learning,
especially computational learning theory and information filtering.
Atsuyoshi Nakamura received his B.S. and M.S. degrees
in computer science from the Tokyo Institute of Technology in 1986
and 1988. He is presently an assistant manager in the
C&C Media Research Laboratories of NEC Corporation.
His interests have been in the area of machine learning,
especially computational learning theory and information filtering.
|
 Naoki Abe received the B.S. and M.S. degrees from the Massachusetts
Institute of Technology in 1984, and the Ph. D. degree from
the University of Pennsylvania in 1989, all in Computer Science.
After holding a post doctoral researcher position at the University of
California, Santa Cruz, he joined NEC Corporation in 1990, where
he is currently principal researcher
in the C&C Media Research Laboratories. He is also visiting
associate professor in the department of computational intelligence
and systems science at the Tokyo Institute of Technology.
His research interests include theory of machine learning and
its applications to various domains, including internet information
mining and navigation.
Naoki Abe received the B.S. and M.S. degrees from the Massachusetts
Institute of Technology in 1984, and the Ph. D. degree from
the University of Pennsylvania in 1989, all in Computer Science.
After holding a post doctoral researcher position at the University of
California, Santa Cruz, he joined NEC Corporation in 1990, where
he is currently principal researcher
in the C&C Media Research Laboratories. He is also visiting
associate professor in the department of computational intelligence
and systems science at the Tokyo Institute of Technology.
His research interests include theory of machine learning and
its applications to various domains, including internet information
mining and navigation.
|
 Tomonari Kamba received his B.E. and M.E., and PhD in Electronics from
the University of Tokyo in 1984, 1986 and 1997 respectively.
He joined NEC Corporation in 1986, and he has been engaged in user
interface design methodology, multimedia user interface, software agent,
and Internet information service technology.
He was a visiting scientist at the Graphics, Visualization&Usability
Center at the College of Computing, Georgia Institute of Technology from
1994 to 1995.
He is now a principal researcher in the C&C Media Research
Laboratories, NEC Corporation.
Dr. Kamba is a member of ACM SIGCHI and the Information Processing
Society of Japan.
Tomonari Kamba received his B.E. and M.E., and PhD in Electronics from
the University of Tokyo in 1984, 1986 and 1997 respectively.
He joined NEC Corporation in 1986, and he has been engaged in user
interface design methodology, multimedia user interface, software agent,
and Internet information service technology.
He was a visiting scientist at the Graphics, Visualization&Usability
Center at the College of Computing, Georgia Institute of Technology from
1994 to 1995.
He is now a principal researcher in the C&C Media Research
Laboratories, NEC Corporation.
Dr. Kamba is a member of ACM SIGCHI and the Information Processing
Society of Japan.
|
 Yoshiyuki
Koseki received his B.S. degree in computer
science from the Tokyo Institute of Technology in 1979 and his
M.S. degree in computer science from the University of
California at Los Angeles in 1981. He received his Ph.D. in
System Science from Tokyo Institute of Technology in 1993. He
joined NEC Corporation in 1981, and has since been engaged in
research on artificial intelligence, expert systems, visual
programming, information visualization, and WWW-based agent
technology. He is now a Senior Research Manager in NEC's C&C
Media Research
Laboratories and is a member of the IEEE, the Japanese
Society for Artificial Intelligence, and the Information
Processing Society of Japan. Yoshiyuki
Koseki received his B.S. degree in computer
science from the Tokyo Institute of Technology in 1979 and his
M.S. degree in computer science from the University of
California at Los Angeles in 1981. He received his Ph.D. in
System Science from Tokyo Institute of Technology in 1993. He
joined NEC Corporation in 1981, and has since been engaged in
research on artificial intelligence, expert systems, visual
programming, information visualization, and WWW-based agent
technology. He is now a Senior Research Manager in NEC's C&C
Media Research
Laboratories and is a member of the IEEE, the Japanese
Society for Artificial Intelligence, and the Information
Processing Society of Japan. |