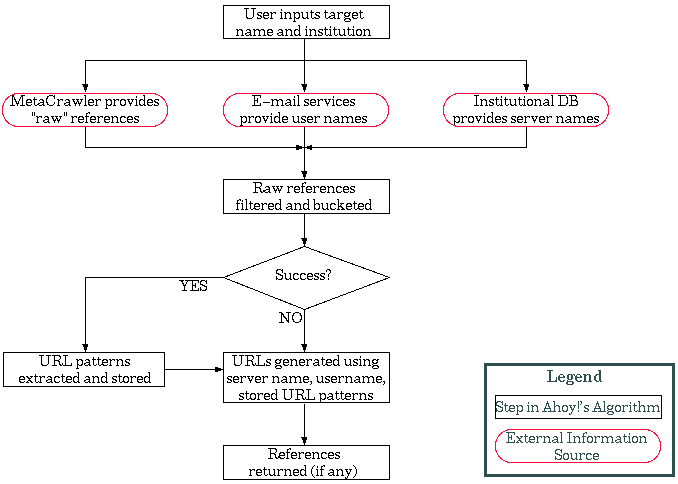
Figure 2. Architecture of Ahoy!
{jshakes|marclang|etzioni}@cs.washington.eduRobot-generated Web indices such as AltaVista are comprehensive but imprecise; manually generated directories such as Yahoo! are precise but cannot keep up with large, rapidly growing categories such as personal homepages or news stories on the American economy. Thus, if a user is searching for a particular page that is not cataloged in a directory, she is forced to query a web index and manually sift through a large number of responses. Furthermore, if the page is not yet indexed, then the user is stymied. This paper presents Dynamic Reference Sifting -- a novel architecture that attempts to provide both maximally comprehensive coverage and highly precise responses in real time, for specific page categories.
To demonstrate our approach, we describe Ahoy! The Homepage Finder (http://www.cs.washington.edu/research/ahoy), a fielded web service that embodies Dynamic Reference Sifting for the domain of personal homepages. Given a person's name and institution, Ahoy! filters the output of multiple web indices to extract one or two references that are most likely to point to the person's homepage. If it finds no likely candidates, Ahoy! uses knowledge of homepage placement conventions, which it has accumulated from previous experience, to "guess" the URL for the desired homepage. The search process takes 9 seconds on average. On 74% of queries from our primary test sample, Ahoy! finds the target homepage and ranks it as the top reference. 9% of the targets are found by guessing the URL. In comparison, AltaVista can find 58% of the targets and ranks only 23% of these as the top reference.
Information sources that are both comprehensive and precise (i.e., point exclusively to relevant web pages) are a holy grail for web information retrieval. Manually generated directories such as Yahoo! [Yahoo!, 1994] or The Web Developer's Virtual Library [CyberWeb, 1997] can be both precise and comprehensive, but only for categories that are relatively small and static (e.g., British Universities); a human editorial staff cannot keep up with large, rapidly growing categories (e.g., personal homepages, news stories on the American economy, academic papers on a topic, etc.). Thus, if a user is searching for a particular page that has yet to be cataloged in a directory, she is forced to query robot-generated web indices such as AltaVista [Digital Equipment Corporation, 1995] or Lycos [Lycos, 1995]. These automatically generated indices are more comprehensive, but their output is notoriously imprecise. As a result, the user is forced to sift manually through a large number of web index responses to find the desired reference.
Even such a laborious approach may not work. The automatically generated indices are not completely comprehensive [Selberg and Etzioni, 1995] for three reasons. First, each index has its own strategy for selecting which pages to include and which to ignore. Second, some time passes before recently minted pages are pointed to and subsequently indexed. Third, as the web continues to grow, automatic indexers begin to reach their resource limitations.
This paper introduces a new architecture for information retrieval tools designed to address the above problems. We call this architecture Dynamic Reference Sifting (DRS). It includes the following key elements:
DRS is by no means appropriate for all web searches. It works best for classes of pages with the following characteristics:
Our fundamental claim is that for these classes of pages, DRS offers significant advantages over the currently popular approaches typified by Yahoo! and AltaVista. To support this claim we developed a DRS search tool for the personal homepage category, which we call Ahoy! The Homepage Finder. Ahoy! was first tested on the web in February, 1996. The most recent version was deployed in July, 1996 and now fields over 2,000 queries per day.
The remainder of this paper is organized as follows:
Sections 2 and 3 contrast
current methods
of finding personal homepages with the
DRS approach
to this problem.
Section 4
evaluates the performance
of DRS techniques in the homepage domain.
We describe related work in Section 5,
discuss future work in Section 6, and
conclude in Section 7.
Many web users have established personal homepages that contain
information such as their address, phone numbers, schedules,
directions for visitors, and so on.
Unfortunately, homepages can be difficult to find. Most
people use one of three methods.
Method 1: Directories.
Some web services such as Yahoo! have attempted to create directories
of homepages by relying on users to register their own pages, but
such efforts have failed so far. As of November 1996,
Yahoo! contains
about 50,000 personal homepages.
It is difficult to say how many personal homepages are on the web,
but it is clear that Yahoo!'s list represents only a small fraction
of the total. For example, it contains only one percent of the
roughly 30,000
personal homepages created by
Netcom subscribers,
and it contains between one and ten percent of homepages in
other samples used to test Ahoy!.
Method 2: General-Purpose Indices.
AltaVista, Hotbot
[Hotbot, 1996],
and other general-purpose indices
make query syntax available
that is tuned to find people. This approach to finding personal
homepages avoids the problems of manually creating a list, but
the output of such searches frequently contains an inconveniently
large number of references. For example, searching AltaVista
for one of our authors using the query
"Oren NEAR Etzioni" returns about 400 references.
A similar search using
Hotbot produces over 800 matches.
A separate problem is that many search tool users do
not bother to learn the
specialized query syntax and thus request an even less precise
search.
Method 3: Manual Search.
When you know enough about a person, you can find his homepage
by first finding the web site of the person's institution, then possibly
searching down to the person's department, and finally locating a list
or index of homepages for people at that site.
Unfortunately, this method can be slow.
If, for example, you were looking for a biologist named Peter Underhill at Stanford
University, you might spend several minutes
looking through web pages of dozens of departments that might
reasonably employ a biologist.
2. Current Methods of Finding Homepages
3. Using DRS to Find Homepages
Search for a Personal Homepage |
Ahoy! represents a fourth approach to finding people's homepages. (Figure 1 shows the fields in Ahoy!'s Web interface.) We believe that Ahoy!'s DRS architecture makes it the most effective tool currently available on the web for this task. Ahoy! combines the advantages of manually-generated directories -- their relevance and reliability -- with the advantage of general-purpose search engines like AltaVista -- their enormous pool of indexed pages. In fact, due to the DRS URL Generator, Ahoy! is able to find and return homepages that are not listed in any search index. Finally, Ahoy! provides the advantage of speed: when it returns a negative result (i.e., it reports that it cannot find a given homepage), it can save its user from scanning through tens or hundreds of "falsely positive" references returned by a general-purpose search engine. In addition, Ahoy! returns a result much faster than a manual search would.
The general design of Ahoy! is shown in Figure 2. Although the behavior of each component is specific to the homepage domain, the general structure of the system could be applied to other domains as well.
Figure 2. Architecture of Ahoy!
To find the search target, a DRS system begins by forwarding the user's input to a reference source and to other, information-providing sources whose output is orthogonal to that of the reference source. In the case of Ahoy!, user input includes the name of a person and, optionally, other descriptors such as his institution and country. Ahoy!'s reference source is the MetaCrawler parallel web search service [Selberg and Etzioni, 1995]; Ahoy! gives the person's name to MetaCrawler and receives a long list of candidate web pages in return. It simultaneously submits the name to two e-mail directory services [WhoWhere?], [IAF], and determines the URL of the target person's institution using an internal database, if the user has completed the appropriate input field. These combined sources of information serve as the input to the next step, filtering.
In the filtering step, a DRS system uses two types of filters to sift out irrelevant references and rank the remaining ones: cross-filtering and heuristic-based filtering. In the homepage domain, cross-filtering helps Ahoy! reject references based on information about the target person's institution and e-mail address. Heuristic-based filtering uses heuristics that deal with people's names and the way most homepages are structured.